Accueil
Accueil Projets Professionnels
Projets Professionnels Modélisation de Business Plan
Modélisation de Business Plan Ticket Marketing
Ticket Marketing Outils de Développement
Outils de Développement Traitement de Données
Traitement de Données Retail PRO
Retail PRO Web / Mobile
Web / Mobile CV Dynamique
CV Dynamique Portfolio
Portfolio Ma Bibliothèque Perso
Ma Bibliothèque Perso Examen en ligne
Examen en ligne Débuts & Jeux
Débuts & Jeux Turbo Pascal + ASM
Turbo Pascal + ASM Windows / Delphi
Windows / DelphiPour le compte de Séphora Asie, qui nécessitait une interface entre Retail PRO (DB Oracle et Import/Export XML) et l’outil « maison » de suivi des colis transportés de GEODIS (Import/Export "CSV" non standard), j’ai développé cette application capable de lire n’importe quel type de fichier XML, CSV, ou requêtes SQL, définir leur structure, transtyper les données, croiser ces données, calculer des champs grâce à des formules (lookup dans d’autres sources, calculs élémentaires, appels de fonctions codées) et ainsi regénérer des fichiers XML et CSV.
Plutôt qu’une approche « one-shot » répondant strictement au besoin du client, j’ai pris le risque d’une approche « outil réutilisable » car hautement configurable, tout en maintenant une utilisation extrêmement simple pour l’utilisateur final, une fois que l’outil a été configuré pour ses besoins.
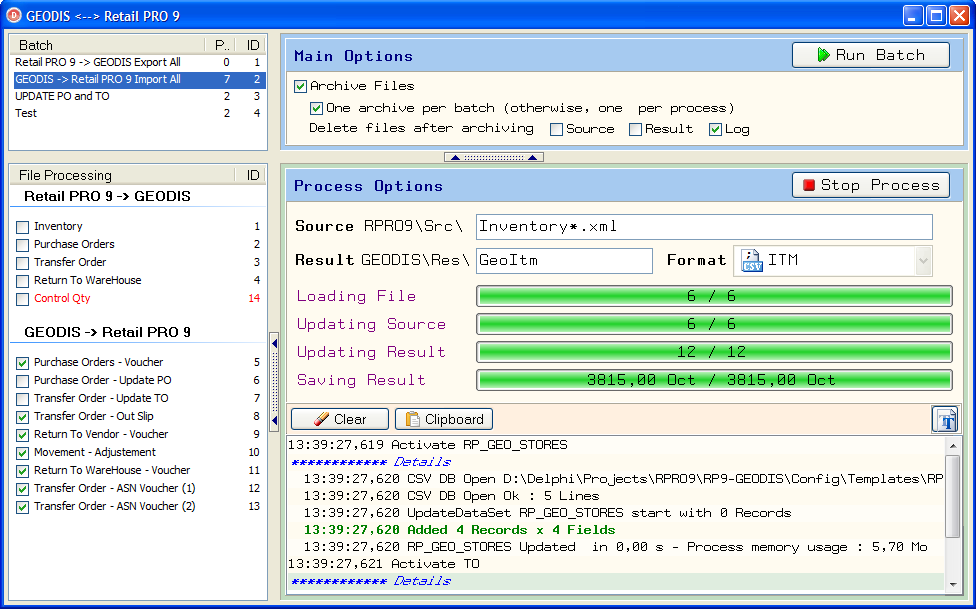
Les traitements sont organisés en process (ou flux de données), eux-mêmes regroupés en batch. Ces batchs peuvent être lancés depuis une interface utilisateur sobre et efficace, ou depuis une application console en ligne de commande qui exécute cette application en tâche de fond et est intégrable dans tout système d’automatisation de tâches.
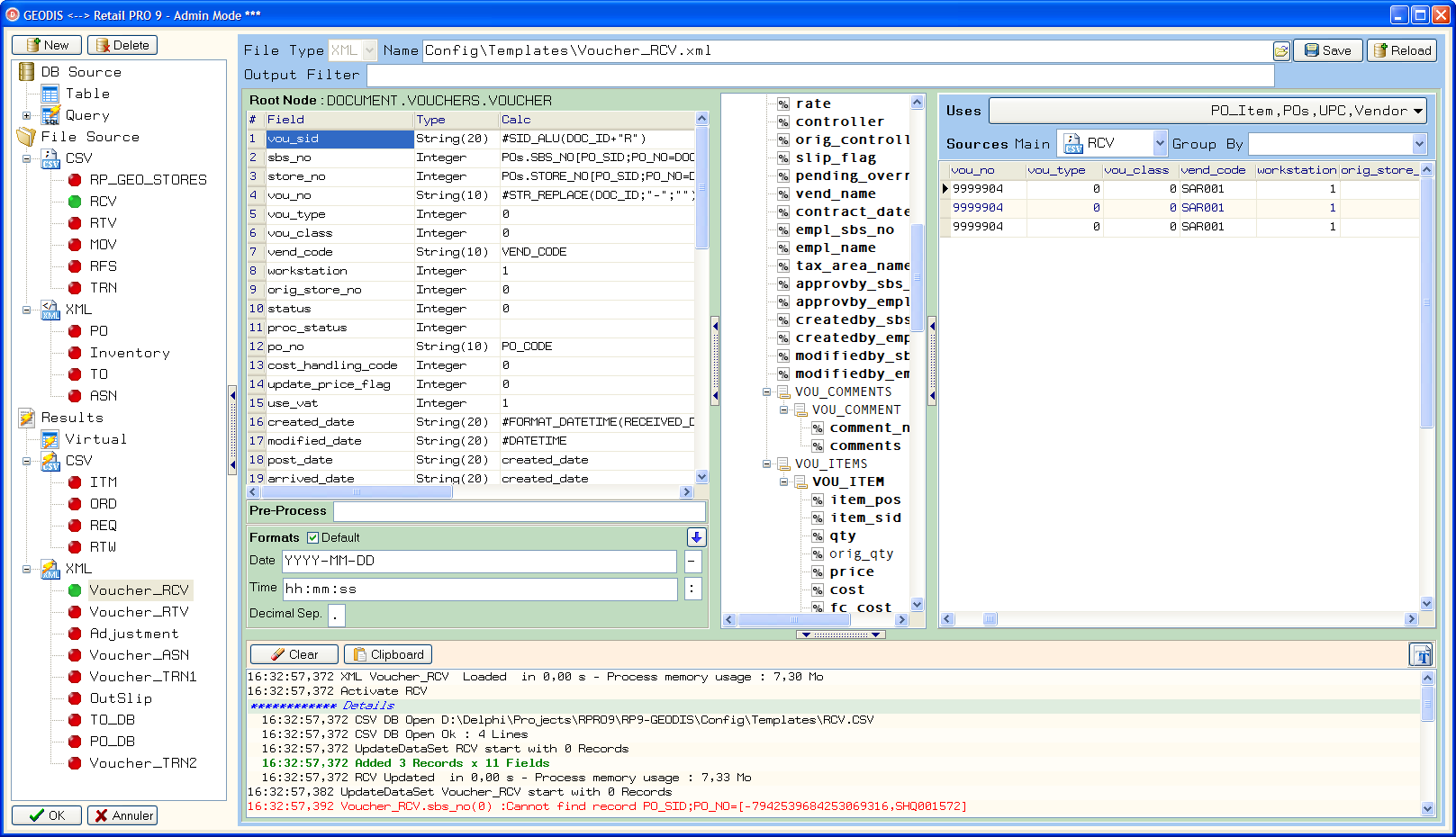
Le cœur du système est construit autour d'un transcodeur de fichiers dont l'objectif est de normaliser les données dans des tables en mémoire. Pour définir le processus de normalisation, une interface part d'un fichier exemple (XML ou CSV), pour identifier les champs de données lors d'une "mise à plat". La même interface permet de définir comment regénérer un fichier identique à partir de données venues d'ailleurs (on a donc deux classes de fichier/normalisation : Source ou Résultat). Des bases de données (Oracle dans ce cas) peuvent également servir de source pour compléter les données des fichiers.
Des "formules" rendent la solution encore plus adaptable, et font le lien entre les sources de données hétérogènes (lookup). Pour construire un fichier résultat, la normalisation part d'une source maître, et d'éventuellement plusieurs autres sources qui servent de référence pour les lookup ou de jointure avec la source principale.
Une fois ce moteur de transcodage réalisé, il fallait créer une interface simple pour parametrer des process de données, qui ont la charge de trouver des ensembles de fichiers d'un certain type (Format Source maître) pour les transcoder (en utilisant un format Résultat) et générer le ou les fichiers de sorties. L'association entre fichiers d'entrées et sortie peut être 1->N, N->1 ou N->N, il faut donc pouvoir définir sur quel(s) champ(s) les données sont regroupés ou éclatés.
Du point de vue utilisateur, une fois les process configurés, il n'y a plus qu'à les exécuter (ou un Batch les regroupant), soit en ligne de commande, soit via l'interface qui se contente d'afficher des progress-bar pour la multitude de traitements qui s'enchainent.
Un point également très important de cette application, est sa capacité de générer des logs hiérarchiques, c'est à dire affichés dans un arbre qui correspond à l'enchainement non-linéaire des tâches de lecture, transcodage, calcul, couplage, génération et sauvegarde. Cela permet en cas de problème d'identifier rapidement à quelle étape le process a relevé des anomalies, et plus facilement remonter jusqu'à la donnée d'origine qui pose un problème.
De plus, les messages du log sont color-coded, rien de tel pour rapidement s'assurer que tout s'est bien passé ou qu'au contraire on a eu des erreurs. C'est vraiment primordial et c'est un atout majeur pour la mise au point de la solution (configuration) et sa maintenance en production.
Lorsque j'ai eu à refaire des traitements de données multi-source, ce projet a été légèrement modifié au niveau de la configuration des process/batch, pour être plus générique et pouvoir accéder à plus de types de base de données, mais dans l'ensemble le cœur est resté le même. Cet outil est devenu alors connu auprès de mes clients réguliers comme "SuperBridge" car faisant le lien avec toutes les sources de données.

Super Bridge
Transcodeur universel de base de données / XML / CSV